Learning CPP via Advent of Code 2024 [Days 1 to 8]
Learning CPP via Advent of Code 2024 [Days 1 to 8]#
I’ve decided to use Advent of Code 2024 as a platform to improve my C++ skills. With a background in C, having worked on Embedded Systems for the past two years, and over five years of experience in Python where I consider myself between intermediate and advanced, I felt it was time to dive into C++. While I’m familiar with core programming concepts like loops, functions, and Object-Oriented Programming (OOP) from my experience in C and Python, I wanted a more practical and engaging way to learn C++ without retreading the basics.
Advent of Code, with its daily coding challenges, seemed like a good way to get hands-on with C++.
This is my attempt to document my learning journey through Advent of Code 2024. Instead of cluttering with each post for each day’s challenge, I’ll be grouping my progress into consolidated posts. This page is the first part of my progress log covering Days 1 to 8.
Full solutions are available on GitHub: ABD-01/AoC2024.
Day 1: Historian Hysteria#
Solution Overview#
Part 1: Sorting and Pairing Numbers#
Given two lists of numbers.
Pair up the
smallest number in the left listwith thesmallest number in the right list, then thesecond-smallest left numberwith thesecond-smallest right number, and so on.
Sort both lists, take absolute difference of the values elementwise and sum it up.
37 std::sort(vec1.begin(), vec1.end()); // sorts in ascending order
38 std::sort(vec2.begin(), vec2.end());
39 //std::ranges::sort(vec2);
40
41 int result = 0;
42 for (std::size_t i = 0; i < vec1.size(); i++)
43 result += abs(vec1[i] - vec2[i]);
Part 2: Calculating Similarity Scores#
Calculate a total
similarity scoreby adding up each number in the left list after multiplying it by the number of times that number appears in the right list.
48 for (std::size_t i = 0; i < vec1.size(); i++)
49 {
50 /**
51 int count = 0;
52 for (std::size_t j = 0; j < vec1.size(); j++)
53 if (vec1[i] == vec2[j])
54 count++;
55 */
56 int count = std::count(vec2.begin(), vec2.end(), vec1[i]);
57 //int count = std::ranges::count(vec2, vec1[i]);
58 result += (count * vec1[i]);
59 }
Now here using std::count inside a loop results in a time complexity of \(O(n^2)\). This could be optimized further using a hash map (std::unordered_map) to count occurrences in \(O(n)\) time.
Concepts Learned#
Reading from a file#
Use file streams defined in header <fstream>
ifstream: Input file stream for reading files.ofstream: Output file stream for writing files.fstream: Input-output file stream for both reading and writing.
String Streams (<sstream>): Used to read from or write to strings.
istringstream: For input operations from a string.ostringstream: For output operations to a string.stringstream: For both input and output operations on a string.
standard input/output streams (<iostream>)
Vectors#
1// 1. Creates a vector 'a' with 'count' elements
2vector<int> a(count);
3
4// 2. Creates a vector 'v' with 'count' elements, all initialized to 'value'
5vector<int> v(count, value);
6
7// 3. Looping over a vector and printing its elements
8for (auto i : vec) std::cout << i << " ";
9
10// 4. Iterators
11std::vector<int>::iterator it = vec.begin();
12auto it = vec.end();
13
14// 5. Methods
15a.size()
16a.push_back // adds an element to the end
Example
1#include <iostream>
2#include <fstream>
3#include <sstream>
4#include <vector>
5
6int main() {
7 std::ifstream file("input.txt");
8 if (!file.is_open()) {
9 std::cerr << "Error opening file!" << std::endl;
10 return 1;
11 }
12
13 std::vector<int> a, b;
14 std::string line;
15 while (std::getline(file, line)) {
16 std::istringstream iss(line);
17 int num1, num2;
18 if (!(iss >> num1 >> num2)) {
19 std::cerr << "Error parsing line!" << std::endl;
20 continue;
21 }
22 a.push_back(num1);
23 b.push_back(num2);
24 }
25
26 file.close();
27
28 return 0;
29}
Ranges#
for ranges, use -std=c++20 during compilation
std::ranges::countcount(v, target2);Same as
std::count(v.begin(), v.end(), target1);
std::ranges::sortSame asstd::sort(vec2.begin(), vec2.end());
Initializer List#
// TODO
explicit specifier#
When a constructor is marked as [explicit](explicit specifier - cppreference.com), the compiler will not use that constructor for implicit type conversions or copy-initialization, meaning it will not automatically convert or create an object from a single argument when the compiler thinks it’s needed (for example, in assignments or function calls).
Example
1#include <iostream>
2
3class MyClass {
4public:
5 explicit MyClass(int x) { std::cout << "Constructor called with " << x << std::endl; }
6};
7
8void display(MyClass obj) {
9 std::cout << "In display function\n";
10}
11
12int main() {
13 // display(10); // Error: no implicit conversion from int to MyClass
14 display(MyClass(10)); // Must explicitly create MyClass
15 return 0;
16}
Insertion Sort#
Code
95template<typename T>
96void insertionSort(T& vec)
97{
98 typename T::iterator first = vec.begin();
99 typename T::iterator last = vec.end();
100
101 for(auto current = first + 1; current != last; current++)
102 {
103 auto key = *current;
104 //auto position = current - 1;
105 auto position = current;
106 for (; position != first && *(position-1) > key; position--)
107 {
108 //*(position+1) = *position;
109 *(position) = *(position-1);
110 }
111 //*(position+1) = key;
112 *(position) = key;
113 }
114 return;
115}
References and Resources#
Sorting (Bubble, Selection, Insertion, Merge, Quick, Counting, Radix) - VisuAlgo
Classes Part 22 - Curly brace versus parenthesis and std::initializer_list| Modern cpp Series Ep. 59
Day 2: Red-Nosed Reports#
Solution Overview#
Part 1: Count Safe Reports#
For a given list of numbers check if
it is all increasing or all decreasing.
Any two adjacent values differ by at least one and at most three.
17bool isReportSafe(const std::vector<int>& v)
18{
19 if (v.size() < 2) return true; // A single-element or empty list is trivially safe.
20
21 bool isSafe = true;
22 // Must be all increasing or all decreasing.
23 bool isSorted = (v[0] > v[1]) // If first element is greater than second, assume it should be decreasing
24 ? std::is_sorted(v.begin(), v.end(), std::greater<int>{})
25 : std::is_sorted(v.begin(), v.end());
26
27 if(!isSorted) return false;
28
29 for (std::size_t i = 1; i < v.size(); ++i)
30 {
31 int diff = abs(v[i]-v[i-1]);
32 // Any two adjacent values must differ by at least one and at most three.
33 if (!(1 <= diff && diff<= 3))
34 {
35 isSafe = false;
36 break;
37 }
38 }
39 // Could also use std::adjacent_find
40 return isSafe;
41}
Part 2: Tolerate a Single Unsafe Report#
For a given list, remove one element and check is it safe or not
64bool part2(const std::vector<int>& vec)
65 for(std::size_t i = 0; i < vec.size(); ++i)
66 {
67 std::vector<int> temp = vec;
68 temp.erase(temp.begin() + i);
69 if (isReportSafe(temp))
70 return true;
71 }
Key Takeaways#
Vector of Vectors#
std::is_sorted and std::greater#
std::adjacent_find#
Source: gcc-mirror/gcc/libstdc++-v3/include/bits/stl_algo.h
Code
1bool funct(const std::vector<int>& vec)
2
3 std::vector<int> v{1, 2, 3, 4, 4, 5};
4 auto it = std::adjacent_find(v.begin(), v.end());
5 if (it != v.end())
6 std::cout << "First pair of repeated elements: " << *it << '\n';
7
8 // Solution using adjacent_find
9 return std::adjacent_find(v.begin(), v.end(),
10 [](int a, int b) {
11 int diff = std::abs(b - a);
12 return diff < 1 || diff > 3;
13 }) == v.end();
std::count_if#
Example
1bool funct(const std::vector<int>& vec)
2#include <algorithm>
3
4bool isSorted = (v[0] > v[1])
5 ? std::is_sorted(v.begin(), v.end(), std::greater<>{})
6 : std::is_sorted(v.begin(), v.end());
7
8return std::adjacent_find(v.begin(), v.end(),
9 [](int a, int b) {
10 int diff = std::abs(b - a);
11 return diff < MIN_DIFF || diff > MAX_DIFF;
12 }) == v.end();
13
14static int countSafeReports(const std::vector<std::vector<int>>& reports)
15{
16 return std::count_if(reports.begin(), reports.end(), isReportSafe);
17}
References and Resources#
Day 3: Mull It Over#
Solution Overview#
Part 1: Multiplication in Trash#
Parse the given corrupted string and look for pattern mul(X,Y), where X and Y are each 1-3 digit numbers. Add up all the results of the multiplications of X and Y.
36 std::istreambuf_iterator<char> it(file), end;
37 auto first = it;
38 auto second = it;
39
40 std::vector<std::pair<int, int>> mulVec;
41 unsigned int result(0);
42
43 for(first = it; it != end; ++it)
44 {
45 if (
46 (char)*first == 'm' &&
47 (char)*++first == 'u' &&
48 (char)*++first == 'l' &&
49 (char)*++first == '('
50 )
51 {
52 bool secondNum = false;
53 unsigned int num1(0), num2(0);
54
55 for(second=++first; second != end; ++second)
56 {
57 if(std::isdigit(*second))
58 {
59 if(secondNum)
60 num2 = num2*10 + (*second - '0');
61 else
62 num1 = num1*10 + (*second - '0');
63 }
64 else if ((char)*second == ',')
65 secondNum=true;
66 else if ((char)*second == ')' && secondNum)
67 {
68 mulVec.emplace_back(num1, num2);
69 result += (num1*num2);
70 break;
71 }
72 else
73 break;
74 }
75 }
76
77 }
Part 2: Do/Don’t Multiply#
There are two new instructions you’ll need to handle:
The
do()instruction enables futuremulinstructions.The
don't()instruction disables futuremulinstructions.
96 std::regex regex(R"((mul\(\d{1,3},\d{1,3}\))|(do\(\))|(don't\(\)))");
97
98 std::sregex_iterator start{ std::sregex_iterator(contents.begin(), contents.end(), regex) };
99 std::sregex_iterator end{ std::sregex_iterator() };
100
101 unsigned int result(0);
102
103 int mulEnabled(1);
104 for (auto i = start; i != end; ++i)
105 {
106 //std::smatch match = *i;
107 std::string match = (*i).str();
108
109 if(match.compare("don't()") == 0)
110 mulEnabled = 0;
111
112 else if (match.compare("do()") == 0)
113 mulEnabled = 1;
114
115 else
116 {
117 int num1(0), num2(0);
118 auto j = 4;
119 while(match[j] != ',')
120 num1 = num1*10 + (match[j++] - '0');
121 ++j;
122 while(match[j] != ')')
123 num2 = num2*10 + (match[j++] - '0');
124
125 result += (mulEnabled * num1 * num2);
126 }
127 }
Concepts Learned#
Stream Iterators#
std::istream_iteratorstd::istreambuf_iteratorRead entire file into a string:
1std::ifstream file(filename);
2std::string contents{std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>()};
3// or into a vector of strings
Tip
When reading characters, std::istream_iterator skips whitespace by default (unless disabled with std::noskipws or equivalent), while std::istreambuf_iterator does not. In addition, std::istreambuf_iterator is more efficient, since it avoids the overhead of constructing and destructing the sentry object once per character.
Regex#
std::cmatchforstd::match_results<const char*>: cannot be used with iterators.std::smatchforstd::match_results<std::string::const_iterator>to be used with iteratorsstd::regex_matchfor entire sequencestd::sregex_iteratorfor iterators, which dereferences tostd::smatch
Examples
1std::regex pattern(R"(mul\(\d{1,3},\d{1,3}\))");
2std::string input = "mul(123,456)";
3if (std::regex_match(input, pattern)) {
4 std::cout << "Pattern matched!" << std::endl;
5}
1 std::regex regex(R"((mul\(\d{1,3},\d{1,3}\))|(do\(\))|(don't\(\)))");
2
3 std::sregex_iterator start{ std::sregex_iterator(contents.begin(), contents.end(), regex) };
4 std::sregex_iterator end{ std::sregex_iterator() };
5
6 for (auto i = start; i != end; ++i)
7 {
8 std::smatch match = *i;
9 cout << match.str() << endl;
10 }
Strings#
std::string::compare: returns 0 if equalstd::stoi- String to Int
References and Resources#
Day4: Ceres Search#
Solution Overview#
Part 1: Find XMAS#
Find the word XMAS in a given grid such that it can be horizontal, vertical, diagonal, written backwards, or even overlapping other words.
70std::vector<std::string> contents = {std::istream_iterator<std::string>(file), std::istream_iterator<std::string>()};
71
72int rows{(int)contents.size()}, cols{(int)contents[0].size()};
73std::stringstream ss{};
74for (auto j = 0; j < cols; ++j)
75{
76 for(auto i = 0; i < rows; ++i)
77 ss << contents[i][j];
78 ss << endl;
79}
80std::vector<std::string> rotated_contents = {std::istream_iterator<std::string>(ss), std::istream_iterator<std::string>()};
81
82std::vector<std::string> diag_contents = get_diagonals(contents);
83std::vector<std::string> antidiag_contents = get_diagonals(contents, true);
84
85int result(0);
86std::string xmas("XMAS");
87std::string samx("SAMX");
88
89// repeat this for rotated_contents, diag_contents, antidiag_contents
90for(const auto& line : contents)
91{
92 for(auto i = 0; i <= line.size() - xmas.size(); ++i)
93 {
94 if(line.substr(i, xmas.size()) == xmas || line.substr(i, samx.size()) == samx)
95 ++result;
96 }
97}
Part 2: Find MAS in X#
find two
MASin the shape of anX.
M.S
.A.
M.S
45 std::vector<std::string> grid = {std::istream_iterator<std::string>(file), std::istream_iterator<std::string>()};
46
47 int rows{(int)grid.size()}, cols{(int)grid[0].size()};
48 int result = 0;
49
50 for (int i = 1; i < rows - 1; ++i)
51 {
52 for(int j = 1; j < cols - 1; ++j)
53 {
54 if(grid[i][j] != 'A') continue;
55 result += checkMAS(grid, i, j, 1) & checkMAS(grid, i, j, -1);
56 }
57 }
58
59bool checkMAS(const std::vector<std::string>& grid, int x, int y, int dir)
60{
61 char c1 = grid[x-1][y-dir];
62 char c2 = grid[x+1][y+dir];
63
64 if(c1 == 'M' && c2 == 'S') return true;
65 if(c2 == 'M' && c1 == 'S') return true;
66 return false;
67}
Key Takeaways#
Get diagonals and AntiDiagonals of a 2d Grid#
Number of diagonals in a Grid: \(R+C−1\)
Code
1 int maxRow = 4;
2 int maxCol = 3;
3
4 std::cout << "Diagonals" << std::endl;
5 int row_start = 0; // begin a 0
6 int col_start = maxCol - 1; // begins at maxCol - 1 (the top-right corner).
7 for (int i = 0; i < maxCol+maxRow-1; ++i) // Iterates over all diagonals
8 {
9 std::cout << i << ": ";
10 row_start += (col_start < 0); // clever mechanism to shift the starting row when column goes out of bounds using `(col_start < 0)`
11 // row_start increments by 1 when col_start goes out of bounds (negative), ensuring the starting row shifts downward.
12 for (
13 int j = std::max(0, col_start), k = row_start; // `j` for columns and `k` for rows
14 j < maxCol && k < maxRow;
15 ++j, ++k
16 )
17 {
18 std::cout << k << "," << j << " ";
19 }
20 --col_start; // shifts the starting column leftward
21 std::cout << std::endl;
22 }
23
24 std::cout << "Anti Diagonals" << std::endl;
25 row_start = 0;
26 col_start = 0; //begins at 0 (the top-left corner)
27 for (int i = 0; i < maxCol+maxRow-1; ++i) // Iterates over all diagonals
28 {
29 std::cout << i << ": ";
30 row_start += (col_start > maxCol-1); // shift row when col goes out of bounds
31 for (
32 int j = std::min(maxCol-1, col_start), k = row_start;
33 j > -1 && k < maxRow;
34 --j, ++k
35 )
36 {
37 std::cout << k << "," << j << " ";
38 }
39 ++col_start; // shifts the starting column rightward
40 std::cout << std::endl;
41 }
42
43/**
44Output:
45Diagonals
460: 0,2
471: 0,1 1,2
482: 0,0 1,1 2,2
493: 1,0 2,1 3,2
504: 2,0 3,1
515: 3,0
52Anti Diagonals
530: 0,0
541: 0,1 1,0
552: 0,2 1,1 2,0
563: 1,2 2,1 3,0
574: 2,2 3,1
585: 3,2
59
60*/
Another method suggested by Claude 3.5
Instead of managing starting points (row_start, col_start) explicitly, we can use the property that:
Diagonal Index: \(k=j−i\)
Anti-Diagonal Index: \(k=i+j\)
Diagonals will have \(k\in[−(C−1),(R−1)]\).
Anti-diagonals will have \(k\in[0,R+C−2]\).
Code
1void printDiagonals(int maxRow, int maxCol) {
2 std::cout << "Diagonals\n";
3 // For main diagonals, points on same diagonal have same (row-col)
4 for (int diff = -(maxCol-1); diff < maxRow; ++diff) {
5 std::cout << (diff + maxCol - 1) << ": ";
6 int startRow = std::max(0, diff);
7 int startCol = startRow - diff;
8 for (int row = startRow; row < maxRow && (row-diff) < maxCol; ++row) {
9 std::cout << row << "," << (row-diff) << " ";
10 }
11 std::cout << '\n';
12 }
13
14 std::cout << "\nAnti Diagonals\n";
15 // For anti-diagonals, points on same diagonal have same (row+col)
16 for (int sum = 0; sum < maxRow + maxCol - 1; ++sum) {
17 std::cout << sum << ": ";
18 int startRow = std::max(0, sum - (maxCol - 1));
19 int endRow = std::min(maxRow - 1, sum);
20 for (int row = startRow; row <= endRow; ++row) {
21 std::cout << row << "," << (sum-row) << " ";
22 }
23 std::cout << '\n';
24 }
25}
Day 5: Print Queue#
Solution Overview#
Part 1: Check Page Order#
The first part of the input contains a list of rules X|Y which states that page X must be printed at some point before page Y. Next part have list page sequences, identify which one of those are in right order.
Iterates over all pairs
(i,j)in the given page sequence wherei<j.For each pair, checking if it violates any of the rule.
If no rule violated, the order is valid.
126bool isOrderValid(const std::vector<int>& o, const std::vector<std::pair<int, int>>& rule)
127{
128 for(auto i=0; i < o.size()-1; ++i)
129 {
130 for(auto j=i+1; j < o.size(); ++j)
131 {
132 for(auto r: rule)
133 {
134 if(o[i] == r.second && o[j] == r.first) // incorrect order
135 {
136 return false;
137 }
138 }
139 }
140 }
141 return true;
142}
This is simply brute force and horrible time complexity of \(O(n^2\times m)\) where \(n\) is length of the page sequence (o.size()) and \(m\) is a number of rules(rule.size()).
Optimization#
A faster solution (aoc2024/day05/solution.cpp at main · UnicycleBloke/aoc2024) (\(O(m\times n)\)) I found on Reddit:
Iterate over rules \(O(m)\)
For each rule find its first and second elements in the sequence (Linear search \(O(2n)\), might short-circuit if first not found \(O(n + n/2)\))
check if both finds follow the rule, based on position they appear in the sequence. Else order is not valid.
More optimized solution would require a Hash Map:
145bool isOrderValid(const std::vector<int>& o, const std::vector<std::pair<int, int>>& rule) {
146 // Map elements in 'o' to their indices for fast lookup
147 std::unordered_map<int, int> indexMap;
148 for (int i = 0; i < o.size(); ++i) {
149 indexMap[o[i]] = i;
150 }
151
152 // Check if any rule is violated
153 for (const auto& r : rule) {
154 if (indexMap.find(r.first) != indexMap.end() && indexMap.find(r.second) != indexMap.end()) {
155 if (indexMap[r.first] > indexMap[r.second]) {
156 // Order is invalid
157 return false;
158 }
159 }
160 }
161 // Order is valid
162 return true;
163}
Bringing time complexity to \(O(m + n)\) as find in Hash Map is \(O(1)\) operation.
// Before
[100%] Built target day5
Part 1: 4790
Elapsed time: 7330 us
Part 2: 6319
Elapsed time: 9174 us
Elapsed time: 45189 us
[100%] Built target run5
// After Optimization
[100%] Built target day5
Part 1: 4790
Elapsed time: 2959 us
Part 2: 6319
Elapsed time: 3437 us
Elapsed time: 38453 us
[100%] Built target run5
Part 2: Sort pages as per the Rules#
For each of the incorrectly-ordered updates, use the page ordering rules to put the page numbers in the right order.
Implemented a bubble sort such that while not sorted keep swapping the elements in incorrect order.
93 for(std::vector<int>& o: incorrect_orders)
94 {
95 while(true)
96 {
97 bool order_valid = true;
98
99 for(auto r: rule)
100 {
101 auto i=0,j=0;
102 for(; i < o.size(); ++i)
103 {
104 if(o[i] == r.first) break;
105 }
106 for(; j < o.size(); ++j)
107 {
108 if(o[j] == r.second) break;
109 }
110
111 if(i==o.size() || j==o.size()) continue;
112 if(j < i)
113 {
114 std::swap(o[i], o[j]);
115 order_valid = false;
116 break;
117 }
118 }
119
120 if (order_valid) break;
121 }
122 }
Found a more optimized solution on the internet, using \(m\times m\) matrix data, where data[a][b] == true means a must come before b in any valid sequence.
Key Takeaways#
std::move#
Example std::move
1 while (std::getline(file, line))
2 {
3 cout << line << endl;
4 std::istringstream iss(line);
5 std::vector<int> pages;
6 std::string page;
7 while (std::getline(iss, page, ','))
8 {
9 pages.push_back(std::stoi(page));
10 }
11 order.push_back(std::move(pages));
12 /**
13 order.push_back(pages); - Copies the content of pages into order
14 order.push_back(std::move(pages)) - Moves the contents, no copying, ownership of interal is transferred
15 When use std::move??
16 -> Don't need the original vector
17 -> performance optimization
18 */
19 }
for loop with pass by reference#
for(auto o: orders): The copy constructor ofstd::vector<int>is called for each element oforders.
1 for(std::vector<int> o: incorrect_orders)
2 {
3 // some condition
4 std::swap(o[i], o[j]);
5 }
6 // Does NOT change the original
7 // Instead do
8 for(std::vector<int>& o: incorrect_orders)
Fun#
![]() Ref: 2024 Day 5 (part 2) Non-Transitivity, non-schmansitivity : r/adventofcode
Ref: 2024 Day 5 (part 2) Non-Transitivity, non-schmansitivity : r/adventofcode
References and Resources#
Day 6: Guard Gallivant#
Solution Overview#
8void Guard::move(std::vector<std::string>& map)
9{
10 map[position.x][position.y] = 'X';
11 Point temp = position+direction;
12
13 if (temp.x < 0 || temp.y < 0 || temp.x >= map.size() || temp.y >= map[0].size())
14 {
15 can_move = false;
16 cout << "Guard left the map" << endl;
17 return;
18 }
19
20 if (map[temp.x][temp.y] == '#' || map[temp.x][temp.y] == 'O')
21 {
22 // Guard hit an obstacle, turn right
23 turnRight();
24 move(map);
25 return;
26 }
27
28 if(is_looping(temp, direction))
29 {
30 can_move = false;
31 stuck_in_loop = true;
32 cout << "Guard stuck in a Loop" << endl;
33 return;
34 }
35
36 position = temp;
37
38 visited.emplace(position, direction);
39}
40
41void Guard::turnRight()
42{
43 //-1,0 -> 0,1
44 // 0,1 -> 1,0
45 // 1,0 -> 0,-1
46 // 0,-1 -> -1,0
47 direction = Point(direction.y, -direction.x);
48}
49
50bool Guard::is_looping(Point p, Point d) const
51{
52 PointMap::const_iterator it = visited.find(p);
53 if (it != visited.end() && it->second == d)
54 return true;
55 return false;
56}
Part 1: Predict the Guard’s Route#
The Guard moves in a 2D grid, turning right upon hitting an obstacle (# or O). The goal is to find the number of distinct positions visited before the Guard exits the map.
Key Logic:
Create an unordered set (\(O(1)\) insert) for visited positions.
If using a vector, check for duplicates before inserting (\(O(n)\)).
Move the Guard until it exits the map.
On obstacle collision → turn right → retry movement.
Return
visited.size()for number of distinct positions.
Part 2: Trap the Guard in a Loop#
You need to get the guard stuck in a loop by adding a single new obstruction. How many different positions could you choose for this obstruction?
Brute force solution would be to iterate over all possible position on the map. A better solution would be to only place obstacles on path that the guard travels.
Created an
unordered_mapto store each visited position with its corresponding direction. (visited.emplace(position, direction))A loop occurs on visiting same position and have same direction as before
33using PointMap = std::unordered_map<Point, Point, PointHash>;
34...
35
36 PointMap guardVisitedPositions = g.getVisited(); // from part 1
37 for(const std::pair<Point, Point>& v: guardVisitedPositions)
38 {
39 int i(v.first.x), j(v.first.y);
40
41 if(i==gx && j==gy) continue;
42
43 map[i][j] = 'O';
44 g = Guard(Point(gx, gy), Guard::dirUp);
45
46 while (g.canMove())
47 {
48 g.move(map);
49 }
50 if(g.stuckInLoop())
51 {
52 ++numObstacles;
53 }
54 map[i][j] = 'X';
55 }
Concepts Learned#
Operator Overload#
Example Operator Overloading for Point Class
1struct Point
2{
3 int x,y;
4 Point(int x, int y): x(x), y(y) {}
5
6 Point operator+(const Point& p)
7 {
8 return Point(x + p.x, y + p.y);
9 }
10 bool operator==(const Point& p) const
11 {
12 return x == p.x && y == p.y;
13 }
14
15}
16std::ostream& operator<<(std::ostream& os, const Point& p)
17{
18 os << "(" << p.x << ", " << p.y << ")";
19 return os;
20}
const Correctness#
We bind type modifiers and qualifiers to the left
Modern C, Jens Gustedt (Page 18)
const X* p1const int* p; // p points to a constant int (can't modify the value it points to) 2int a = 5; 3p = &a; // okay, p can point to another int 4*p = 10; // error, can't modify the value of a through p
X const* p1int const* p; // Same as `const int* p`
X* const p1int* const p = &a; // p is a constant pointer, it always points to the same location 2*p = 10; // okay, the value of the object p points to can be modified 3p = &b; // error, can't change p to point to another object
const X* const p1const int* const p = &a; // p is a constant pointer to a constant int 2*p = 10; // error, can't modify the value of the object p points to 3p = &b; // error, can't change p to point to another object
The
constat the end of member function does not modify the state of object.
1class Fred {
2public:
3 void inspect() const; // This member promises NOT to change *this
4 void mutate(); // This member function might change *this
5};
6void userCode(Fred& changeable, const Fred& unchangeable)
7{
8 changeable.inspect(); // Okay: doesn't change a changeable object
9 changeable.mutate(); // Okay: changes a changeable object
10 unchangeable.inspect(); // Okay: doesn't change an unchangeable object
11 unchangeable.mutate(); // ERROR: attempt to change unchangeable object
12}
const Point&Return type
1class Guard
2{
3public:
4 // Getter functions to access position and direction
5 const Point& getPosition() const { return position; }
6 const Point& getDirection() const { return direction; }
7 /**
8 By returning a constant reference (const Point&), you provide read-only access to the position and direction.
9 This ensures that the caller cannot modify the values.
10 */
Dangling References#
1const int& getTemp() {
2 int temp = 10; // Local variable
3 return temp; // Dangling reference (temp goes out of scope)
4}
5
6Point p1(1, 2);
7const int& a = p1.getX();
8p1 = Point(3, 4); // a now refers to a destroyed object!
In C++, there is no built-in way to directly check if a reference is dangling
Unordered set#
Used Hash Table to store elements
Steps to use unordered_set with a custom class:
Define a hash function for your
Pointclass.Override
==operator to check for equality, asunordered_setuses it to compare elements.Use the custom hash function in
unordered_set.
Example Code
1struct Point
2{
3 int x,y;
4 Point(int x, int y): x(x), y(y) {}
5 Point() : x(0), y(0) {}
6
7 Point operator+(const Point& p) const
8 {
9 return Point(x + p.x, y + p.y);
10 }
11 bool operator==(const Point& p) const
12 {
13 return x == p.x && y == p.y;
14 }
15};
16struct HashPoint {
17 std::size_t operator()(const Point& p) const {
18 return std::hash<int>()(p.x) ^ (std::hash<int>()(p.y) << 1);
19 }
20};
21std::unordered_set<Point, HashPoint> visited;
For unordered_set of std::pair<Point, Point>
Code
1// Define a custom hash for std::pair<Point, Point>
2struct PairHash {
3 size_t operator()(const std::pair<Point, Point>& pair) const {
4 PointHash pointHash;
5 // Combine the hash values of the two points in the pair
6 return pointHash(pair.first) ^ (pointHash(pair.second) << 1);
7 }
8};
9
10// Overload equality operator for std::pair<Point, Point>
11struct PairEqual {
12 bool operator()(const std::pair<Point, Point>& a, const std::pair<Point, Point>& b) const {
13 return a.first == b.first && a.second == b.second;
14 }
15};
16/** This can also be omitted
17The == operator for std::pair is already defined (since std::pair is a standard library type).
18It compares both elements of the pair for equality.
19*/
20
21std::unordered_set<std::pair<Point, Point>, PairHash, PairEqual> pointPairs;
22std::unordered_set<std::pair<Point, Point>, PairHash> point_pairs;
23
24// Aliases
25using PointSet = std::unordered_set<Point, PointHash>;
26using PointPairSet = std::unordered_set<std::pair<Point, Point>, PairHash>;
Unordered Map#
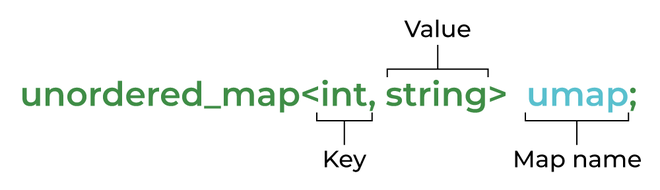
1std::unordered_map<Point, Point, PointHash> visited;
2
3// ### Check if value is in HashMap
4std::map<char,int> mymap;
5std::map<char,int>::iterator it;
6
7if (visited.find(current) != visited.end() && visited[current] == direction) {
8 return true;
9}
10// If current is not already in the map, accessing visited[current] will insert a new entry
11
12auto it = visited.find(current);
13if (it != visited.end() && it->second == direction) {
14 return true;
15}
16
17// ### Looping through HashMap
18for(const std::pair<Point, Point>& v: visited)
19{
20 cout << v.first << ":" << v.second << endl;
21}
Static Constant Members in C++ Classes#
static constis used for class-level constants, meaning these constants are shared across all instances of the class.The
statickeyword ensures the constant is a class-wide (not instance-specific) member, whileconstensures the values cannot be modified.Static members must be defined outside the class, even if they’re
const.You cannot initialize static members within constructors. Integral types you can initialize inline at their declaration.
1class Guard{
2public:
3 static const Point dirUp, dirDown, dirLeft, dirRight;
4 static const int a = 4; // works
5};
6const Point Guard::dirUp(-1, 0);
7const Point Guard::dirDown(1, 0);
8const Point Guard::dirLeft(0, -1);
9const Point Guard::dirRight(0, 1);
References and Resources#
c++ - What is the meaning of ‘const’ at the end of a member function declaration? - Stack Overflow
How to create an unordered_set of user defined class or struct in C++? - GeeksforGeeks or unordered set - How can I use a C++ unordered_set for a custom class? - Stack Overflow
hash - C++ unordered_map using a custom class type as the key - Stack Overflow
How to initialize a “static const” data member in C++? - Stack Overflow
Day 7: Bridge Repair#
Solution Overview#
Part 1: Given a test value and a list of numbers, determine whether the numbers can be combined using the operators + (addition) and * (multiplication) to produce the test value
Operators are always evaluated left-to-right, not according to precedence rules.
Part 2: Introduces a third operator: concatenation (||), alongside + and *.
Using a recursive call, with using one operator from left at each call.
68using ll = long long;
69
70bool check_target1(const std::vector<int>& operands, int index, ll current_value, ll target)
71{
72 // reached end and found thr test value
73 if(index==(int)operands.size()) return current_value == target;
74
75 // If current value is already greater than the target, no point in continuing
76 // small improvement by short circuiting
77 if(current_value > target) return false;
78
79 // subtle Bug! You only want to check for equality when list is exhausted
80 //if(current_value == target) return true;
81
82 return check_target1(operands, index+1, current_value + operands[index], target)
83 || check_target1(operands, index+1, current_value * operands[index], target);
84}
85
86bool check_target2(const std::vector<int>& operands, int index, ll current_value, ll target)
87{
88 if(index==(int)operands.size()) return current_value == target;
89
90 if(current_value > target) return false;
91
92 return check_target2(operands, index+1, current_value + operands[index], target)
93 || check_target2(operands, index+1, current_value * operands[index], target)
94 || check_target2(operands, index+1, concat(current_value, operands[index]), target);
95}
96
97void part(const std::vector<std::pair<ll, std::vector<int>>>& data)
98{
99 ll result = 0;
100 for(const std::pair<ll, std::vector<int>>& d: data)
101 if(check_target(d.second, 0, 1, d.first))
102}
The time complexity is \(O(n^2)\) for Part 1and \(O(n^3)\) for Part 2. While this works, it can be optimized.
Optimization#
With each recursive call the current_value increases. One way to optimize is to process the operations in reverse order, starting from the right, and try to undo the operations to see if the target value can be constructed. resulting in current value to be 0 at the end.
For example:
Given 292: 11 6 16 20, the goal is to check if 292 can be made from these numbers.
The left-to-right approach:
[11+6, 16, 20]→[17*16, 20]→[292]The right-to-left approach:[11, 6, 16, 292-20]→[11, 6, 272/16]→[11, 17-6]→[11-11]→[0]To undo concatenation (||), thecheck_int_containsfunction is used to check if an integer is present in another integer.
134bool check_target1_v2(const std::vector<int>& operands, int index, ll target)
135{
136 if(index < 0) return target == 0 || target == 1;
137
138 if(target < 0) return false;
139
140 if(target % operands[index] == 0)
141 {
142 if(check_target1_v2(operands, index-1, target/operands[index]))
143 return true;
144 // Here too there can be a subtle Bug
145 // if you return check_target1_v2(i-1, target/operands[i])
146 // it fails to account for check_target1_v2(i-1, target-operands[i])
147 // example: 103304: 269 4 96 8
148 }
149
150 return check_target1_v2(operands, index-1, target-operands[index]);
151}
152bool check_int_contains(ll target, ll subint, ll& new_target)
153{
154 int lt, ls;
155 while(subint > 0)
156 {
157 lt = target % 10;
158 target /= 10;
159 ls = subint % 10;
160 subint /= 10;
161 if(lt != ls)
162 {
163 return false;
164 }
165 }
166 new_target = target;
167 return true;
168}
169
170bool check_target2_v2(const std::vector<int>& operands, int index, ll target)
171{
172 if(index < 0) return target == 0 || target == 1;
173
174 if(target < 0) return false;
175
176 if(target % operands[index] == 0)
177 {
178 if(check_target2_v2(operands, index-1, target/operands[index]))
179 return true;
180 }
181
182 ll new_target;
183 if(check_int_contains(target, operands[index], new_target))
184 {
185 if(check_target2_v2(operands, index-1, new_target))
186 return true;
187 }
188
189 return check_target2_v2(operands, index-1, target-operands[index]);
190}
While the time complexity still remains the same, there is significant improvement in the time taken. {emphasize-lines=”5,7,9,11”}
[100%] Linking CXX executable day7.exe
Copying input.txt to input7.txt
[100%] Built target day7
Part 1: 6392012777720
Elapsed time: 2283 us
Part 2: 61561126043536
Elapsed time: 121022 us
Part 1 (Version 2): 6392012777720
Elapsed time: 1268 us
Part 2 (Version 2): 61561126043536
Elapsed time: 1498 us
[100%] Built target run7
Concepts Learned#
Subsets of an array/vector using bit manipulation#
For an array of size \(n\), there are \(2^n\) possible subsets.
Each subset corresponds to a binary number between
0and \(2^n - 1\).
Example
1// ### Problem: Find All Subsets That Sum to a Target Value
2#include <iostream>
3#include <vector>
4using namespace std;
5
6void findSubsetsThatSumToTarget(vector<int>& nums, int target) {
7 int n = nums.size();
8 vector<vector<int>> result;
9
10 // Iterate over all possible subsets
11 for (int mask = 0; mask < (1 << n); mask++) {
12 vector<int> subset;
13 int sum = 0;
14
15 // Generate the subset for the current bitmask
16 for (int i = 0; i < n; i++) {
17 if (mask & (1 << i)) { // If the i-th bit is 1, include nums[i]
18 subset.push_back(nums[i]);
19 sum += nums[i];
20 }
21 }
22
23 // Check if the subset sum equals the target
24 if (sum == target) {
25 result.push_back(subset);
26 }
27 }
28
29 // Print the result
30 cout << "Subsets that sum to " << target << ":\n";
31 for (auto& subset : result) {
32 cout << "[ ";
33 for (int num : subset) {
34 cout << num << " ";
35 }
36 cout << "]\n";
37 }
38}
39
40int main() {
41 vector<int> nums = {2, 3, 5};
42 int target = 5;
43 findSubsetsThatSumToTarget(nums, target);
44 return 0;
45}
References and Resources#
Day 8: Resonant Collinearity#
Solution Overview#
The grid is parsed into a dictionary (unordered_map<char, vector<Vec2<int>>>) with antenna labels as the key and a list of all the label’s positions as values.
Part 1: Find the Antinodes#
an antinode occurs at any point that is perfectly in line with two antennas of the same frequency - but only when one of the antennas is twice as far away as the other.
The words are complicated, see the diagram below. Basically, an antinode is a point that lies on the line extending from a pair of antennas at an equal distance beyond one of them
..........
...#......
..........
....a.....
..........
.....a....
..........
......#...
..........
..........
Logic:
iterate over each pair of antennas with the same frequency.
for each pair, compute the distance between the two antennas and calculate the potential antinode positions on either side of the pair.
Check if the antinodes lie within the grid boundaries, and if they do, add them to an
unordered_setto ensure uniqueness.
128std::unordered_set<int> antinodes;
129for(const std::pair<const char, std::vector<V2>>& antenas: data)
130{
131 const std::vector<V2>& a = antenas.second;
132 for(int i = 0; i < static_cast<int>(a.size()); ++i)
133 {
134 for (int j = i + 1; j < static_cast<int>(a.size()); ++j)
135 {
136 // Calculate distance and antinode positions
137 V2 dist = a[i] - a[j];
138 V2 antinode1(a[i] + dist), antinode2(a[j] - dist);
139
140 // Check if antinode positions are within bounds
141 if(antinode1.x < maxX && antinode1.y < maxY && antinode1.x >= 0 && antinode1.y >= 0)
142 {
143 antinodes.insert(antinode1.x * maxY + antinode1.y);
144 }
145 if(antinode2.x < maxX && antinode2.y < maxY && antinode2.x >= 0 && antinode2.y >= 0)
146 {
147 antinodes.insert(antinode2.x * maxY + antinode2.y);
148 }
149 }
150 }
151}
To track the unique antinode positions, we need to map each (x, y) coordinate to a unique integer value. This is done by using a simple mathematical formula: antinode1.x*maxY + antinode1.y
Part 2: I mean Harmonic Antinodes#
it turns out that an antinode occurs at any grid position exactly in line with at least two antennas of the same frequency, regardless of distance. This means that some of the new antinodes will occur at the position of each antenna (unless that antenna is the only one of its frequency).
Again, the words doesn’t explain much, see the diagram. Similar to Part 1, but instead of stopping at the first antinode, continue along the line of collinearity to count all antinodes.
T....#....
...T......
.T....#...
.........#
..#.......
..........
...#......
..........
....#.....
..........
Logic:
for each pair, compute the distance between the two antennas and calculate the potential antinode positions on either side of the pair.
expand the antinode positions by moving along the calculated distance in both directions until we reach the boundary of the grid.
176while(antinode1.x < maxX && antinode1.y < maxY && antinode1.x >= 0 && antinode1.y >= 0)
177{
178 antinodes.insert(antinode1.x * maxY + antinode1.y);
179 antinode1 += dist; // Move along the distance
180}
181while(antinode2.x < maxX && antinode2.y < maxY && antinode2.x >= 0 && antinode2.y >= 0)
182{
183 antinodes.insert(antinode2.x * maxY + antinode2.y);
184 antinode2 -= dist; // Move along the distance
185}
Concepts Learned#
Operator Overloading for custom class#
Operator overloading to work with the custom Vec2 class representing a 2D vector. This allows to simplify the code when working with positions and distances, such as adding, subtracting, or comparing positions.
Example
1template <typename T>
2struct Vec2
3{
4 T x, y;
5 Vec2(T x_val, T y_val) : x(x_val), y(y_val) {}
6};
7
8using V2 = Vec2<int>;
9using mapV2 = std::unordered_map<char, std::vector<Vec2<int>>>;
10
11template <typename T> Vec2<T> constexpr operator+(Vec2<T> a, Vec2<T> b) { return {a.x + b.x, a.y + b.y}; }
12template <typename T> Vec2<T> constexpr operator-(Vec2<T> a, Vec2<T> b) { return {a.x - b.x, a.y - b.y}; }
13template <typename T> Vec2<T> constexpr operator-(Vec2<T> a) { return {-a.x, -a.y}; }
14template <typename T> Vec2<T> constexpr operator*(Vec2<T> a, Vec2<T> b) { return {a.x * b.x, a.y * b.y}; }
15template <typename T> Vec2<T> constexpr operator*(Vec2<T> a, T b) { return {a.x * b, a.y * b}; }
16template <typename T> Vec2<T> constexpr &operator+=(Vec2<T> &a, Vec2<T> b) { a = a + b; return a; }
17template <typename T> Vec2<T> constexpr &operator-=(Vec2<T> &a, Vec2<T> b) { a = a - b; return a; }
18template <typename T> bool constexpr operator==(Vec2<T> a, Vec2<T> b) { return a.x == b.x && a.y == b.y; }
19template <typename T>
20std::ostream& operator<<(std::ostream& os, const Vec2<T>& v)
21{
22 os << "(" << v.x << "," << v.y << ")";
23 return os;
24}
25
26template <typename T>
27std::ostream& operator<<(std::ostream& os, const std::vector<T>& v)
28{
29 os << "[";
30 for (auto i = v.begin(); i != v.end(); ++i) {
31 if (i != v.begin()) os << ", ";
32 os << *i;
33 }
34 os << "]";
35 return os;
36}
Constexpr#
Enable compile-time evaluation of simple functions, improving performance. // TODO: write in detail
this pointer#
// TODO
Unique Number for each element in 2D grid#
for \(arr[i][j]\) \(\rightarrow\) \(i\times Cols + j\), where \(Cols\) is number of columns.
This marks the first part of my Advent of Code 2024 journey. More updates soon. If you’re also learning C++ or participating in Advent of Code, I’d love to hear about your experiences! Share your thoughts, tips, or solutions in the comments below. Feel free to check out my solutions on GitHub.”
Comments